8. データ処理の基礎と可視化(見える化)
目次
- 8.1 平均・合計・最大値・最小値を求めてみよう
- 8.2 テスト結果からクラスの傾向を読む
- 8.3 matplotlib で簡単なグラフを描いてみる(折れ線図)
- 8.4 軸ラベルやタイトルを付けて分かりやすくする
- 8.5 棒グラフや散布図にも挑戦!
- 8.6 目で見て理解しやすい「見える化」の力
- 8.7 部活の練習データなど身近な情報をグラフ化
- Ex.1 クラス全員の点数をグラフ化し、平均点を表示するプログラム
- Ex.2 部活動の練習日数を棒グラフで表示し、タイトルやラベルを付けるプログラム
この講座で使用する Google Colab の URL
8. データ処理の基礎と可視化(見える化) (Google Colab)
演習課題
Ex.8. データ処理の基礎と可視化(見える化) (Google Colab)
この講座で使用する Python, Jupyter Notebook のファイルと実行環境
Lesson 8: high-school-python-code (GitHub)
8.1 平均・合計・最大値・最小値を求めてみよう
基本的な統計量の計算方法を学んでいきましょう。プログラムを使うと、大量のデータでも簡単に統計量を求めることができます。
データ分析の基本ステップ
データ分析を始める際、まず最初に行うのが「基本統計量」の確認です。基本統計量とは、データの特徴を数値で表したものです。主に以下のような値を指します:
- 合計(Sum): すべての値を足し合わせた値
- 平均(Average / Mean): 合計をデータの個数で割った値
- 最大値(Maximum): データの中の最も大きな値
- 最小値(Minimum): データの中の最も小さな値
これらの値を知ることで、データの概要を素早く把握することができます。Python では、これらの計算を簡単に行うための関数が用意されています。
テストの点数データで統計量を求めてみよう
例として、10 人分のテストの点数データから基本統計量を求めてみましょう。
テストの点数データ
# テストの点数データ
scores = [78, 85, 92, 67, 88, 73, 95, 82, 89, 70]
# 基本的な統計量の計算
total = sum(scores) # 合計
average = total / len(scores) # 平均
maximum = max(scores) # 最大値
minimum = min(scores) # 最小値
print(f"合計点:{total}")
print(f"平均点:{average:.1f}") # 小数点以下 1 桁まで表示
print(f"最高点:{maximum}")
print(f"最低点:{minimum}")
このコードを実行すると、以下のような結果が得られます:
合計点:819
平均点:81.9
最高点:95
最低点:67
Python の組み込み関数で簡単に計算
Python には、基本統計量を簡単に計算するための関数が標準で組み込まれています:
| 関数 | 説明 | 使用例 |
|---|---|---|
sum() | リストの合計を計算 | sum(scores) |
len() | リストの要素数(長さ)を返す | len(scores) |
max() | リストの最大値を返す | max(scores) |
min() | リストの最小値を返す | min(scores) |
これらの関数を使えば、どんなに大きなデータでも瞬時に計算できます。手計算では時間がかかる作業も、プログラムを使えば一瞬で終わらせることができます。
8.2 テスト結果からクラスの傾向を読む
より実践的にテスト結果のデータを整理して、クラス全体の傾向を分析する方法を学びましょう。
クラスの学力傾向を把握する重要性
テストの平均点や最高点だけでなく、クラス全体のデータを分析することで、以下のような有益な情報が得られます:
- 教科ごとの得意・不得意の傾向
- クラス内の学力差(ばらつき)
- 特定の単元の理解度
- 前回のテストからの成長や変化
こうした情報は、効果的な学習計画を立てる上で非常に役立ちます。Python を使えば、このような分析を簡単に行うことができます。
statistics モジュール
Python には statistics という標準ライブラリがあり、より詳しい統計計算を簡単に行うことができます。
statistics モジュールの基本
import statistics
# サンプルデータ
data = [75, 82, 91, 68, 88, 85, 77, 93, 84, 79]
# 基本統計量の計算
mean = statistics.mean(data) # 平均値
median = statistics.median(data) # 中央値
# mode は、 Python 3.8 以降では、同率一位の場合は最初に出現した値を返します
mode = statistics.mode(data) # 最頻値 (モード)
# range とすると Python の range 関数と値が被るので、range_ とします
range_ = max(data) - min(data) # 範囲
iqr = statistics.quantiles(data, n=4)[2] - statistics.quantiles(data, n=4)[0] # 四分位範囲
stdev = statistics.stdev(data) # 標準偏差
variance = statistics.variance(data) # 分散
print(f"平均値: {mean:.1f}")
print(f"中央値: {median}")
print(f"最頻値: {mode}")
print(f"範囲: {range}")
print(f"四分位範囲: {iqr}")
print(f"標準偏差: {stdev:.2f}")
print(f"分散: {variance:.2f}")
これらの統計量については、次の 9 章で詳しく学びます。今はこれらのような用語だけ頭に入れておいてください。
- 平均値(Mean): すべての値の合計をデータ数で割った値
- 中央値(Median): データを小さい順に並べたときに真ん中に来る値
- 最頻値(Mode): データの中で最も頻繁に出現する値
- 範囲(Range): データの最大値と最小値の差
- 四分位範囲(Interquartile Range): データを小さい順に並べたときに、下から 25% の位置と 75% の位置の値の差
- 標準偏差(Standard Deviation): データのばらつきを表す指標
- 分散(Variance): 標準偏差の二乗(ばらつきの大きさ)
複数教科のテスト結果を分析しよう
実際の学校では、複数の教科のテスト結果があります。それぞれの教科ごとに傾向を分析してみましょう。
テスト結果からクラスの傾向を読む
import statistics
# テストの点数データ (各教科 10 人分)
test_scores = {
"国語": [75, 82, 91, 68, 88, 85, 77, 93, 84, 79],
"数学": [82, 79, 88, 92, 75, 85, 88, 90, 78, 84],
"英語": [88, 85, 92, 78, 85, 82, 87, 95, 89, 83]
}
for subject, scores in test_scores.items():
# 基本統計量の計算
mean = statistics.mean(scores) # 平均
median = statistics.median(scores) # 中央値
stdev = statistics.stdev(scores) # 標準偏差
print(f"\n{subject}の分析結果:")
print(f"平均点:{mean:.1f}")
print(f"中央値:{median}")
print(f"標準偏差:{stdev:.1f}")
print(f"点数分布:{min(scores)} ~ {max(scores)}")
実行結果は以下のようになります:
国語の分析結果:
平均点:82.2
中央値:83.0
標準偏差:7.7
点数分布:68 ~ 93
数学の分析結果:
平均点:84.1
中央値:84.5
標準偏差:5.6
点数分布:75 ~ 92
英語の分析結果:
平均点:86.4
中央値:85.5
標準偏差:4.9
点数分布:78 ~ 95
この分析結果から、次のような傾向を読み取ることができます。
- 平均点:英語 > 数学 > 国語 の順で高い
- 標準偏差:国語 > 数学 > 英語 の順で大きい
- 点数分布:英語は最低点が高く(78点)、最高点も高い(95点)
標準偏差が大きいほど、クラス内の点数のばらつきが大きいことを意味します。国語は標準偏差が 7.7 と最も大きいため、得意な人と不得意な人の差が大きいと言えます。
得点の分布
さらに詳しい分析として、得点分布の割合を調べてみましょう。
得点の分布
import statistics
# 国語のテスト結果
japanese_scores = [75, 82, 91, 68, 88, 85, 77, 93, 84, 79]
# 得点帯ごとの人数をカウント
ranges = {
"90点以上": 0,
"80-89点": 0,
"70-79点": 0,
"60-69点": 0,
"60点未満": 0,
}
for score in japanese_scores:
if score >= 90:
ranges["90点以上"] += 1
elif score >= 80:
ranges["80-89点"] += 1
elif score >= 70:
ranges["70-79点"] += 1
elif score >= 60:
ranges["60-69点"] += 1
else:
ranges["60点未満"] += 1
print("国語の得点分布:")
for range_name, count in ranges.items():
percentage = count / len(japanese_scores) * 100
print(f"{range_name}: {count}人 ({percentage:.1f}%)")
8.3 matplotlib で簡単なグラフを描いてみる(折れ線図)
データの基本的な分析方法を見ていきましたが、数字の羅列だけでは傾向を把握するのが難しい場合があります。
そこで、データを「見える化」するためのグラフ作成方法を学びましょう。Python では、グラフ描画ライブラリである matplotlib を使うことで、Python のプログラムからグラフを作成することができます。
下準備:Matplotlib で日本語表示をできるようにする
matplotlib は、Google Colab 上で使うことができます!
ただ、そのままでは日本語を表示することができず、このスクリーンショットのようになってしまいます。
これを解決するためには、以下のコードを実行します。
!pip install japanize-matplotlib
Successfully installed japanize-matplotlib-1.1.3 のように表示されれば、インストール成功です!
すでにインストールされている場合は、Requirement already satisfied: ... のように表示されます。
インストールができたら、Google Colab の中で matplotlib を使うときに、この 1 行を追加します。
import japanize_matplotlib
折れ線グラフを描いてみよう
まずは基本的な折れ線グラフから始めてみましょう。例として、1 週間の気温データをグラフ化します。
日々の気温データ
# matplotlib の pyplot モジュールをインポートします
# 慣習として、 plt という名前で名前付きインポートをすることが多いです
import matplotlib.pyplot as plt
import japanize_matplotlib
# 日々の気温データ
days = list(range(1, 8)) # 1 週間分の日付 [1, 2, 3, 4, 5, 6, 7]
temperatures = [22, 24, 23, 25, 26, 24, 23] # 各日の気温(℃)
# グラフの作成
plt.figure(figsize=(10, 6)) # グラフのサイズ指定(幅 10 インチ、高さ 6 インチ)
plt.plot(days, temperatures, marker='o') # 折れ線グラフの描画、各点に丸印を付ける
# グラフの表示
plt.title('1週間の気温変化') # グラフのタイトル
plt.xlabel('日付') # x 軸のラベル
plt.ylabel('気温(℃)') # y 軸のラベル
plt.grid(True) # グリッド線の表示
plt.show() # グラフを画面に表示
このコードを実行すると、1 週間の気温変化を示す折れ線グラフが表示されます。plt.plot() 関数が折れ線グラフを描画する中心的な関数です。
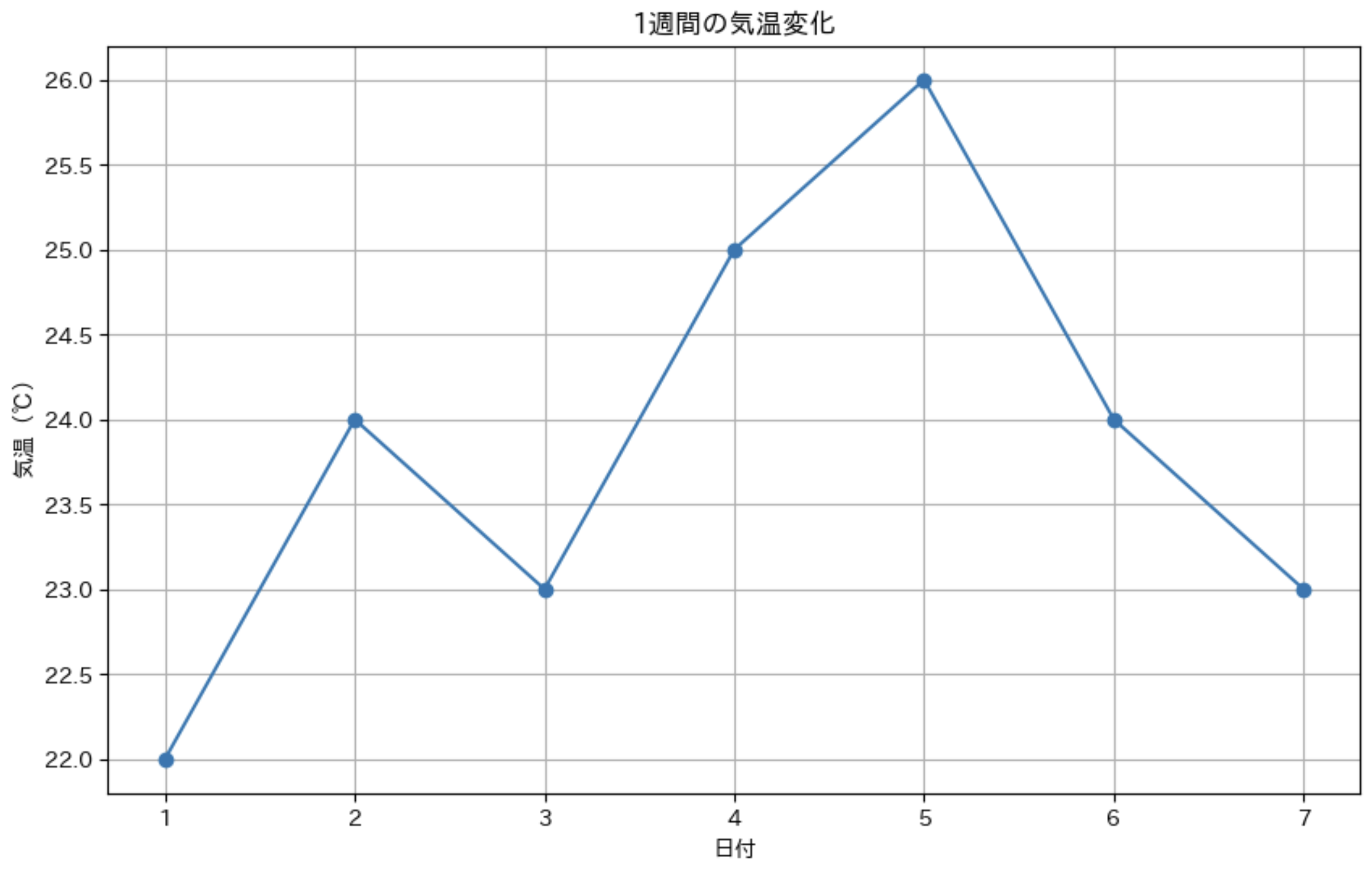
グラフ作成のステップは以下の通りです。
- データの準備: グラフ化したいデータを用意する
- グラフの初期化:
plt.figure()でグラフのキャンバス(枠)を作成 - グラフの描画:
plt.plot()などの関数でグラフを描く - 装飾の追加: タイトル、軸ラベル、グリッド線などを追加
- グラフの表示:
plt.show()でグラフを表示する
8.4 軸ラベルやタイトルを付けて分かりやすくする
データの可視化では、「何を伝えたいのか」を明確にすることが大切です。適切なタイトルや軸ラベル、凡例などを付けることで、グラフが伝える情報が分かりやすくなります。基本的な要素はこれらです。
- タイトル (title):グラフの内容を端的に表す
- 軸ラベル (xlabel, ylabel):X軸とY軸が何を表しているかを示す
- 凡例 (legend):複数データの区別を説明する
- グリッド線 (grid):値を正確に読み取るための補助線
- データラベル (text):重要な点の値を直接表示する
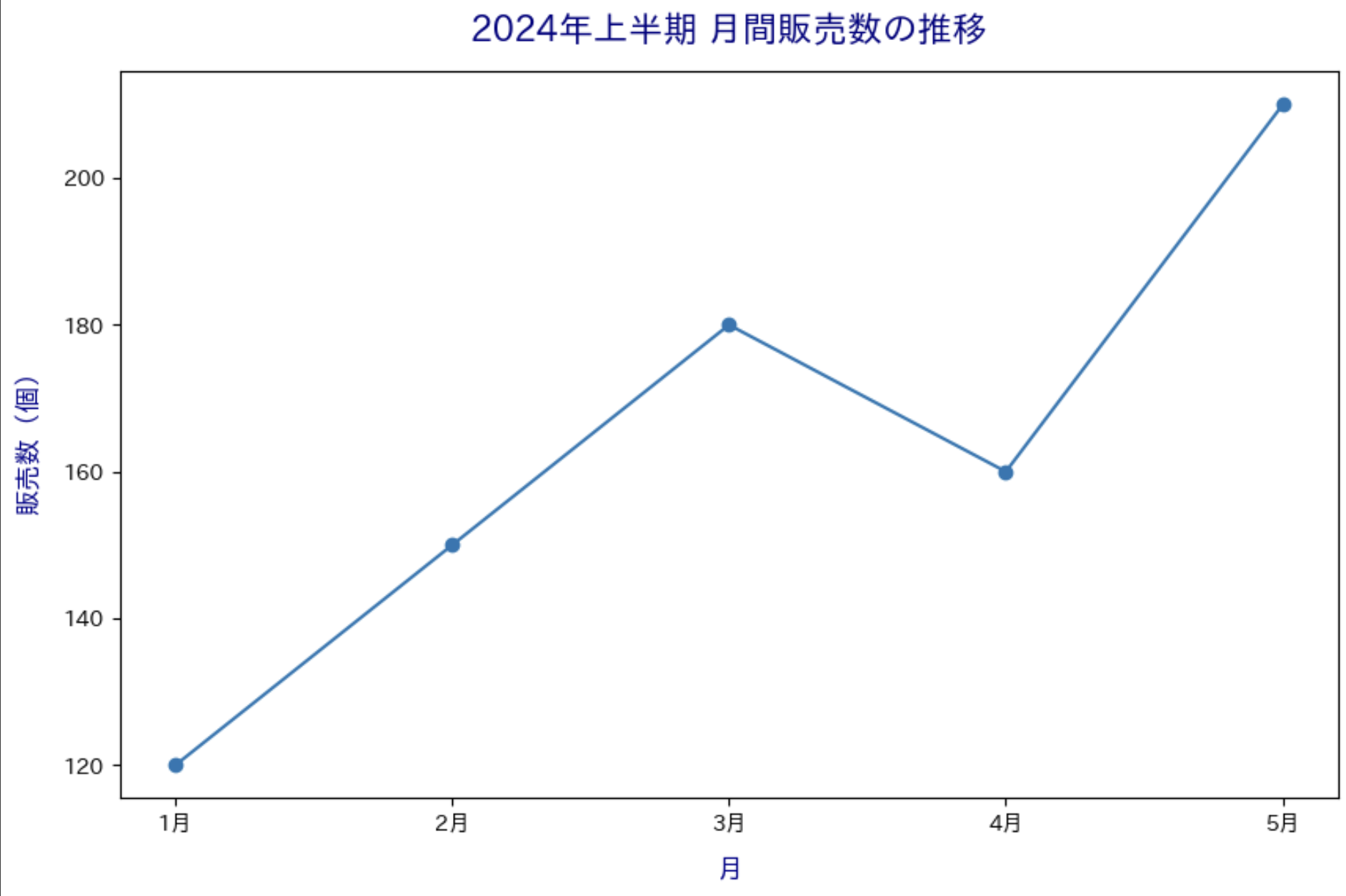
タイトルと軸ラベルのカスタマイズ
タイトルと軸ラベルは、グラフの「顔」とも言える重要な要素です。
タイトルと軸ラベルの詳細設定
import matplotlib.pyplot as plt
import japanize_matplotlib
# データ
months = ['1月', '2月', '3月', '4月', '5月']
sales = [120, 150, 180, 160, 210]
plt.figure(figsize=(10, 6))
plt.plot(months, sales, marker='o')
# タイトルの詳細設定
plt.title(
'2024年上半期 月間販売数の推移',
fontsize=16, # フォントサイズ
fontweight='bold', # 太字
color='navy', # 色
pad=15 # タイトルと図の間隔
)
# 軸ラベルの詳細設定
plt.xlabel('月', fontsize=12, labelpad=10, color='darkblue')
plt.ylabel('販売数(個)', fontsize=12, labelpad=10, color='darkblue')
plt.show()
グリッド線と目盛りの調整
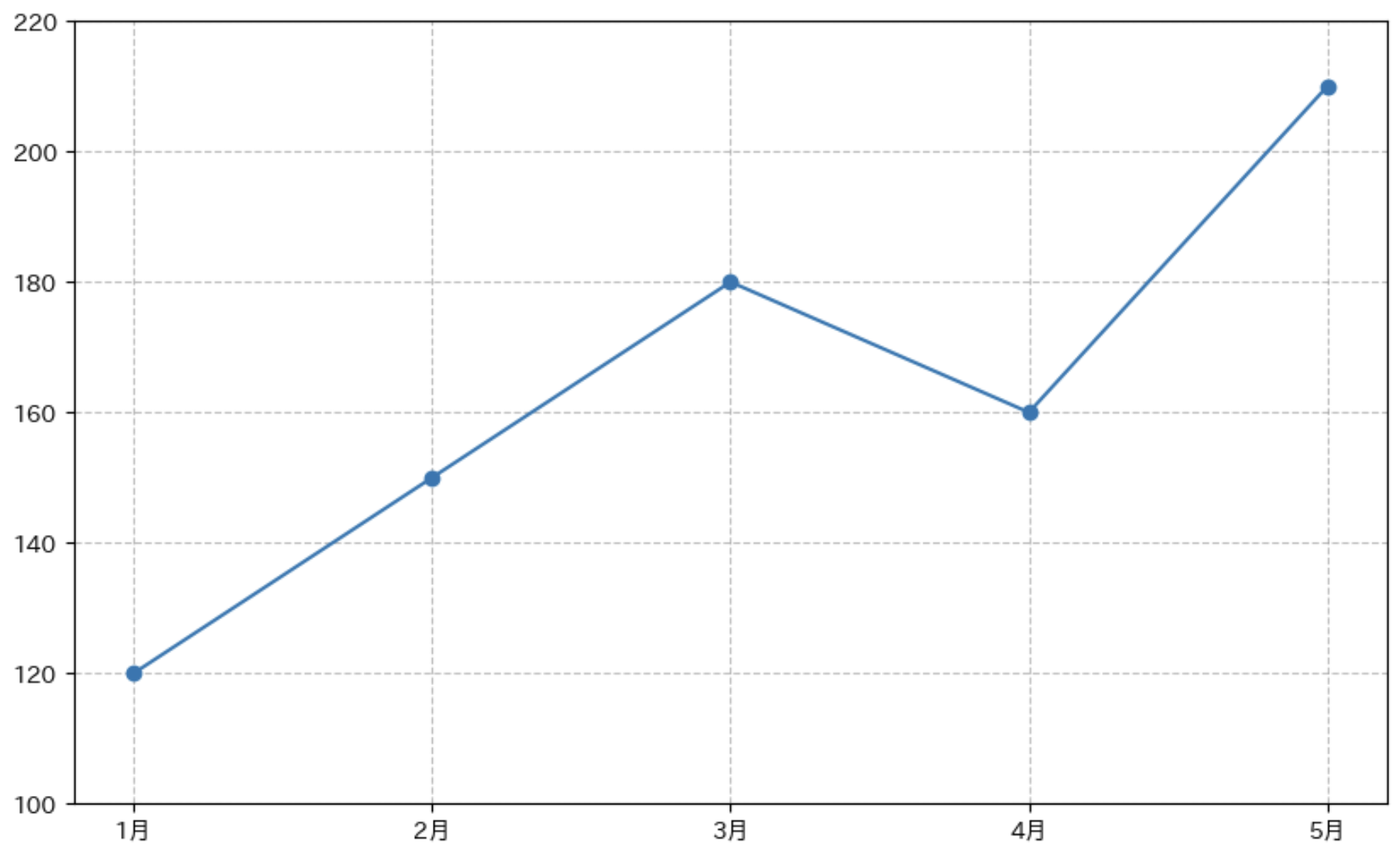
グリッド線や目盛りを調整することで、グラフから値を読み取りやすくなります。
グリッド線と目盛りの調整
import matplotlib.pyplot as plt
import japanize_matplotlib
months = ['1月', '2月', '3月', '4月', '5月']
sales = [120, 150, 180, 160, 210]
plt.figure(figsize=(10, 6))
plt.plot(months, sales, marker='o')
# グリッド線の詳細設定
plt.grid(
True, # グリッド線を表示
axis='both', # x 軸と y 軸の両方にグリッド線
linestyle='--', # 破線スタイル
color='gray', # 色
alpha=0.5 # 透明度
)
# 目盛りの設定
plt.xticks(fontsize=10) # x 軸目盛りのフォントサイズ
plt.yticks(range(100, 221, 20), fontsize=10) # y 軸目盛りの範囲と間隔を指定
plt.show()
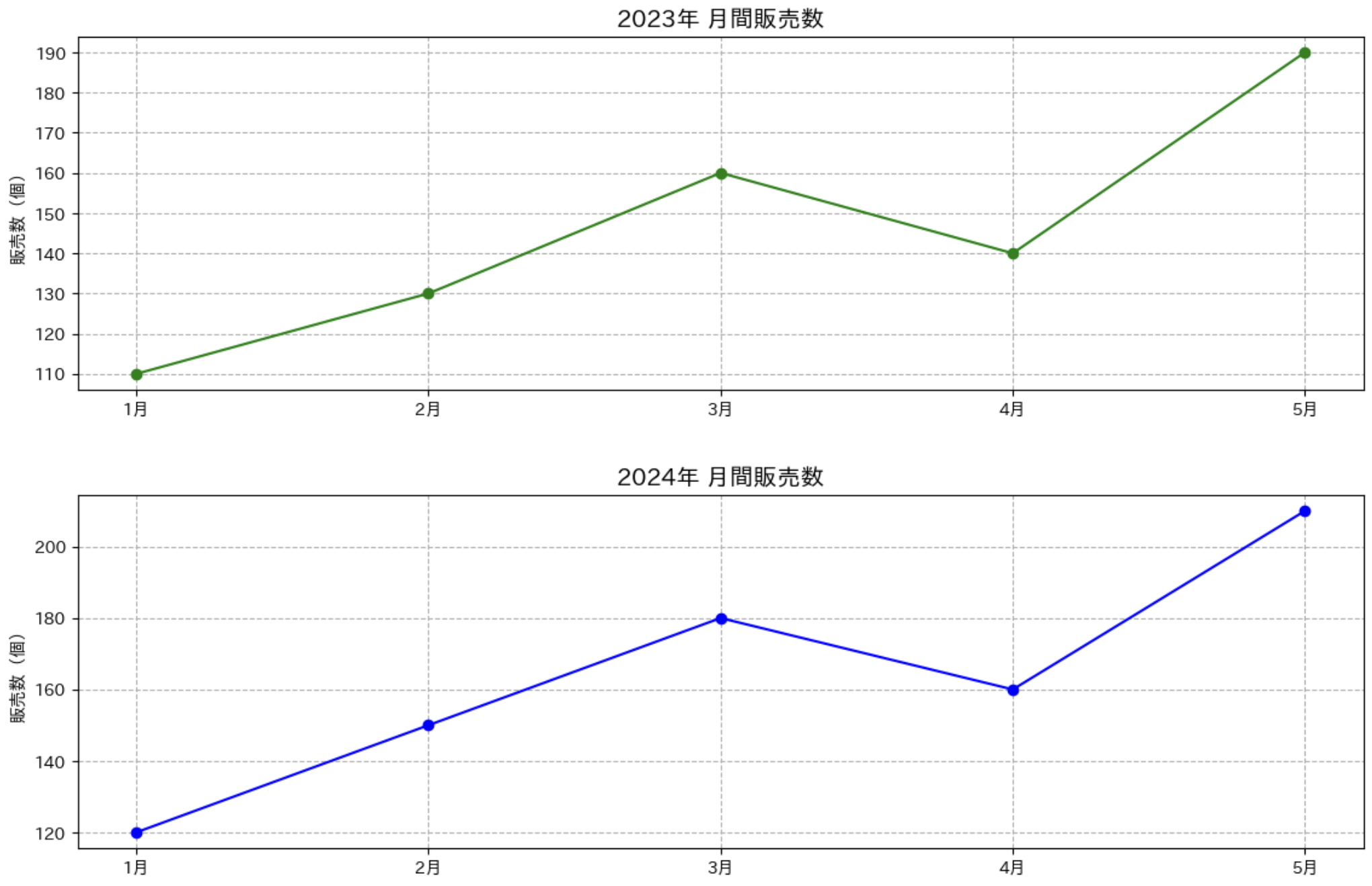
複数のグラフを並べて表示する(サブプロット)
関連する複数のデータを比較したい場合は、サブプロットを使って複数のグラフを並べて表示することもできます。
複数のグラフを並べて表示
import matplotlib.pyplot as plt
import japanize_matplotlib
months = ['1月', '2月', '3月', '4月', '5月']
sales_2023 = [110, 130, 160, 140, 190]
sales_2024 = [120, 150, 180, 160, 210]
# 2 × 1 のサブプロット (2 行 1 列) を作成
plt.figure(figsize=(12, 8))
# 1 つ目のサブプロット (2023 年データ)
plt.subplot(2, 1, 1) # 2 行 1 列の 1 番目
plt.plot(months, sales_2023, marker='o', color='green')
plt.title('2023年 月間販売数', fontsize=14)
plt.ylabel('販売数(個)')
plt.grid(True, linestyle='--')
# 2 つ目のサブプロット (2024 年データ)
plt.subplot(2, 1, 2) # 2 行 1 列の 2 番目
plt.plot(months, sales_2024, marker='o', color='blue')
plt.title('2024年 月間販売数', fontsize=14)
plt.ylabel('販売数(個)')
plt.grid(True, linestyle='--')
# サブプロット間の余白を調整
plt.tight_layout(pad=3.0)
plt.show()
8.5 棒グラフや散布図にも挑戦!
データの種類や分析の目的によって、最適なグラフの種類は異なります。よく使われる棒グラフと散布図の作成方法を学びましょう!
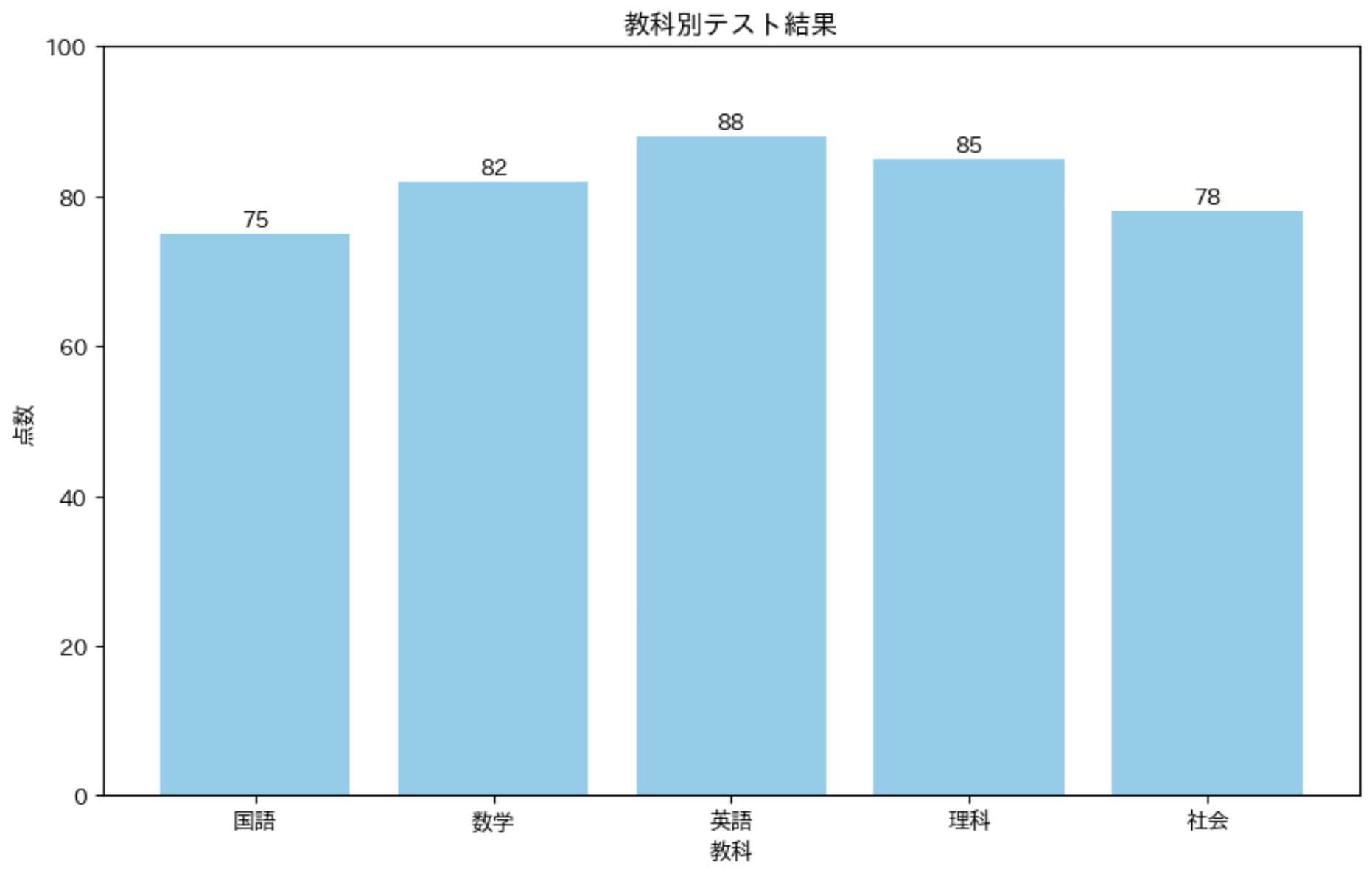
棒グラフを作成しよう
棒グラフは、カテゴリ別のデータを比較するのに最適です。例えば、教科ごとのテスト結果を比較してみましょう。
matplotlib での棒グラフ作成は、plt.bar() 関数を使います。第 1 引数にカテゴリ(ここでは教科名)、第 2 引数に値(ここではテストの点数)を渡します。
教科別テスト結果
import matplotlib.pyplot as plt
import japanize_matplotlib
# データの準備
subjects = ['国語', '数学', '英語', '理科', '社会']
scores = [75, 82, 88, 85, 78]
# 棒グラフの作成
plt.figure(figsize=(10, 6))
plt.bar(subjects, scores, color='skyblue')
# グラフの装飾
plt.title('教科別テスト結果')
plt.xlabel('教科')
plt.ylabel('点数')
# Y 軸の範囲を 0 〜 100 に設定
plt.ylim(0, 100)
# 各棒の上に数値を表示
for i, score in enumerate(scores):
plt.text(i, score + 1, str(score), ha='center')
plt.show()
散布図を作成しよう
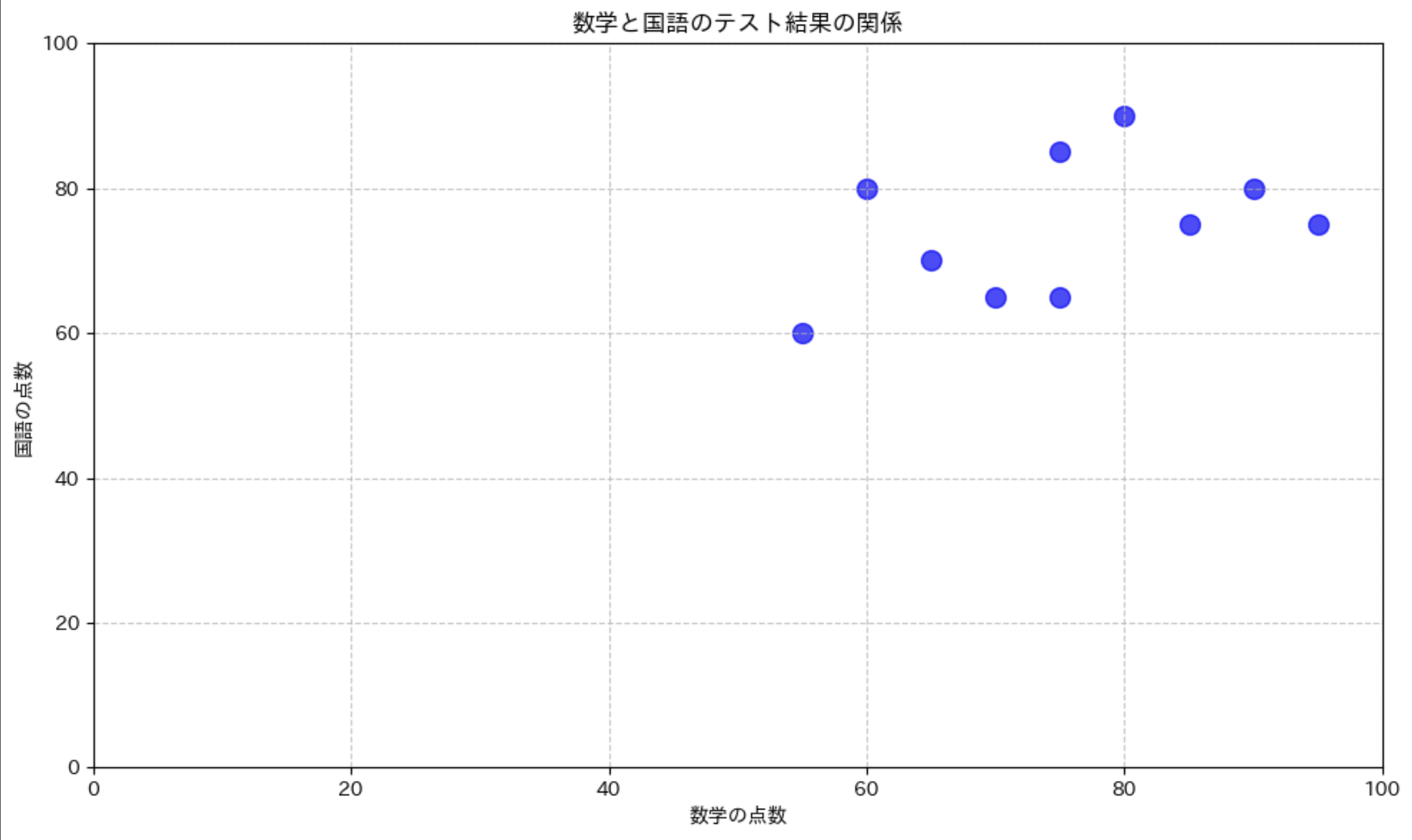
2つの変数の関係性を調べるには、散布図が最適です。例えば、数学と国語のテスト得点の関係を見てみましょう。
散布図は plt.scatter() 関数で作成します。第 1 引数に X 軸のデータ、第 2 引数に Y 軸のデータを渡します。s パラメータでマーカーのサイズを、alpha パラメータで透明度を調整できます。
散布図の基本
import matplotlib.pyplot as plt
import japanize_matplotlib
# データの準備
math_scores = [65, 75, 60, 85, 70, 80, 75, 90, 95, 55] # 数学の点数
japanese_scores = [70, 65, 80, 75, 65, 90, 85, 80, 75, 60] # 国語の点数
# 散布図の作成
plt.figure(figsize=(10, 6))
plt.scatter(math_scores, japanese_scores, color='blue', alpha=0.7, s=100)
# グラフの装飾
plt.title('数学と国語のテスト結果の関係')
plt.xlabel('数学の点数')
plt.ylabel('国語の点数')
plt.grid(True, linestyle='--', alpha=0.7)
# 軸の範囲を設定 (0 〜 100 点)
plt.xlim(0, 100)
plt.ylim(0, 100)
# グラフの余白を調整
plt.tight_layout()
plt.show()
8.6 目で見て理解しやすい「見える化」の力
私たちは日々、膨大な量のデータに囲まれています。しかし、生のデータのままでは、そこに含まれる意味やパターンを見つけるのは難しいことがあります。データの可視化 (Data Visualization) をすることで、情報を直感的に理解しやすくなります。
効果的なデータ可視化の選び方
データを効果的に可視化するには、目的に合ったグラフの種類を選ぶことが重要です。以下は代表的なグラフと、それぞれが得意とする表現です:
| 可視化の種類 | 得意とする表現 | 例 |
|---|---|---|
| 円グラフ | 全体に対する割合 | クラスの男女比、予算の内訳 |
| 棒グラフ | カテゴリ間の比較 | 教科別の平均点、都道府県別人口 |
| 折れ線グラフ | 時間経過による変化 | 気温の推移、成績の変化 |
| 散布図 | 2つの変数間の関係 | 勉強時間とテスト点数の関係 |
| ヒストグラム | データの分布状況 | テスト点数の分布、身長の分布 |
| 箱ひげ図 | データのばらつき | クラス間の点数分布の比較 |
同じデータでも見え方が違う
同じデータでも、表示方法によって印象が大きく変わることがあります。以下の例で見てみましょう。
同じデータの異なる表現
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
# 月間の天気データ
weather_data = {'晴れ': 18, '曇り': 8, '雨': 4}
# 1. 数値データとして表示
print("月間の天気データ:")
for weather, days in weather_data.items():
print(f"{weather}: {days}日")
# 2. 円グラフとして表示
plt.figure(figsize=(10, 6))
plt.subplot(1, 2, 1) # 1 行 2 列の 1 番目
plt.pie(weather_data.values(),
labels=weather_data.keys(),
autopct='%1.1f%%', # パーセント表示
colors=['lightskyblue', 'lightgray', 'lightgreen'])
plt.title('今月の天気の割合(円グラフ)')
# 3. 棒グラフとして表示
plt.subplot(1, 2, 2) # 1 行 2 列の 2 番目
plt.bar(weather_data.keys(), weather_data.values(), color=['lightskyblue', 'lightgray', 'lightgreen'])
plt.title('今月の天気の日数(棒グラフ)')
plt.ylabel('日数')
plt.tight_layout()
plt.show()
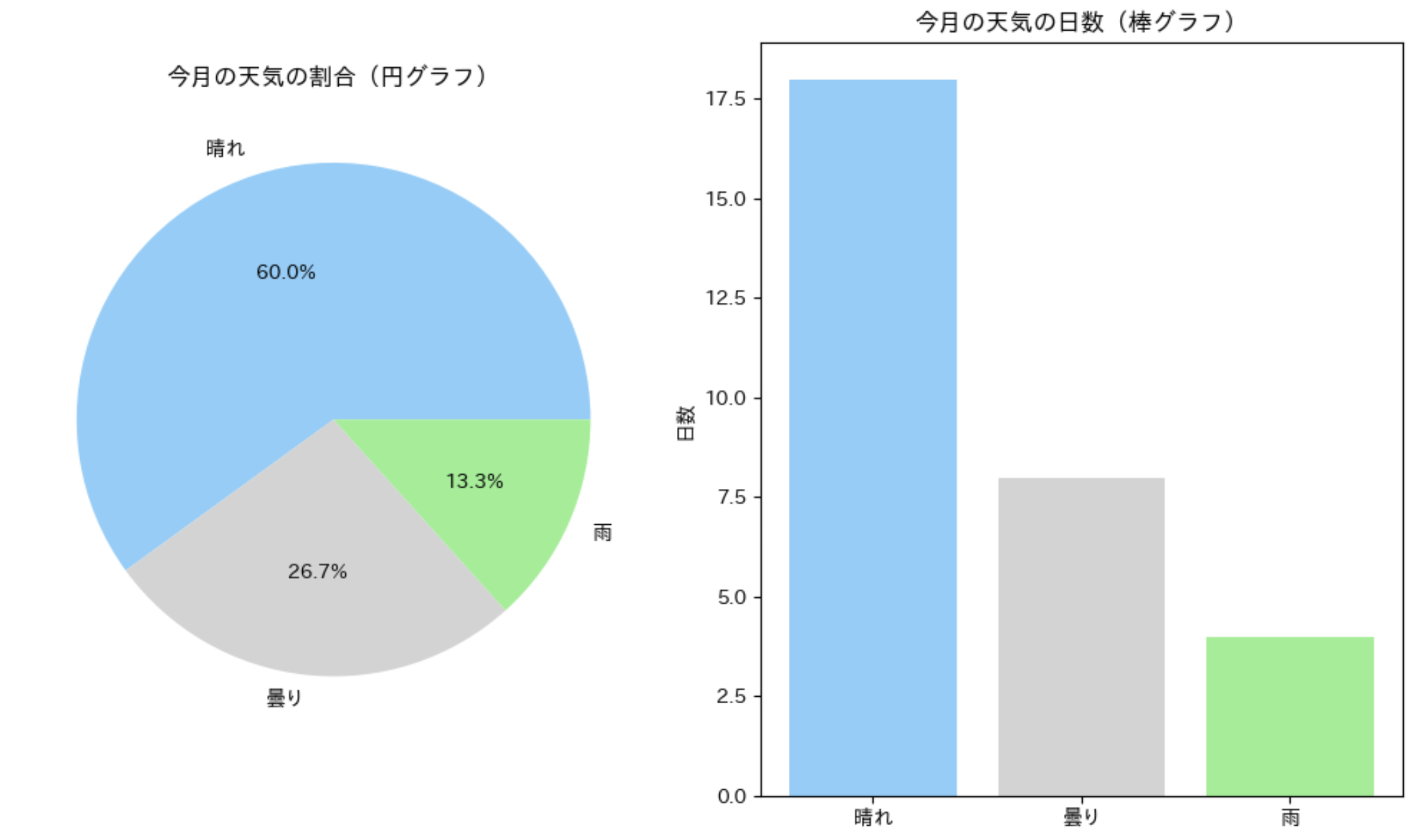
同じデータでも円グラフでは「晴れの日が全体の何%を占めるか」という割合の観点が強調され、棒グラフでは「晴れの日と雨の日の日数の差」という絶対値の比較が分かりやすくなります。
視覚的な錯覚に注意
データ可視化では「嘘をつかない」という倫理的な側面も大切です。意図的でなくても、視覚的な錯覚を引き起こす可能性があります。
同じデータでも印象が変わる例
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
months = ['1月', '2月', '3月', '4月', '5月']
sales = [100, 105, 103, 106, 110]
# 2 つのグラフを並べて表示
plt.figure(figsize=(12, 5))
# 1 つ目: Y 軸が 0 から始まるグラフ
plt.subplot(1, 2, 1)
plt.plot(months, sales, marker='o', linewidth=2, color='blue')
plt.title('売上推移(Y 軸: 0 〜 120)')
plt.ylabel('売上(万円)')
plt.ylim(0, 120) # Y 軸の範囲を 0 〜 120 に設定
plt.grid(True)
# 2 つ目: Y 軸が狭い範囲のグラフ
plt.subplot(1, 2, 2)
plt.plot(months, sales, marker='o', linewidth=2, color='blue')
plt.title('売上推移(Y 軸: 95 〜 115)')
plt.ylabel('売上(万円)')
plt.ylim(95, 115) # Y 軸の範囲を 95 〜 115 に設定
plt.grid(True)
plt.tight_layout()
plt.show()
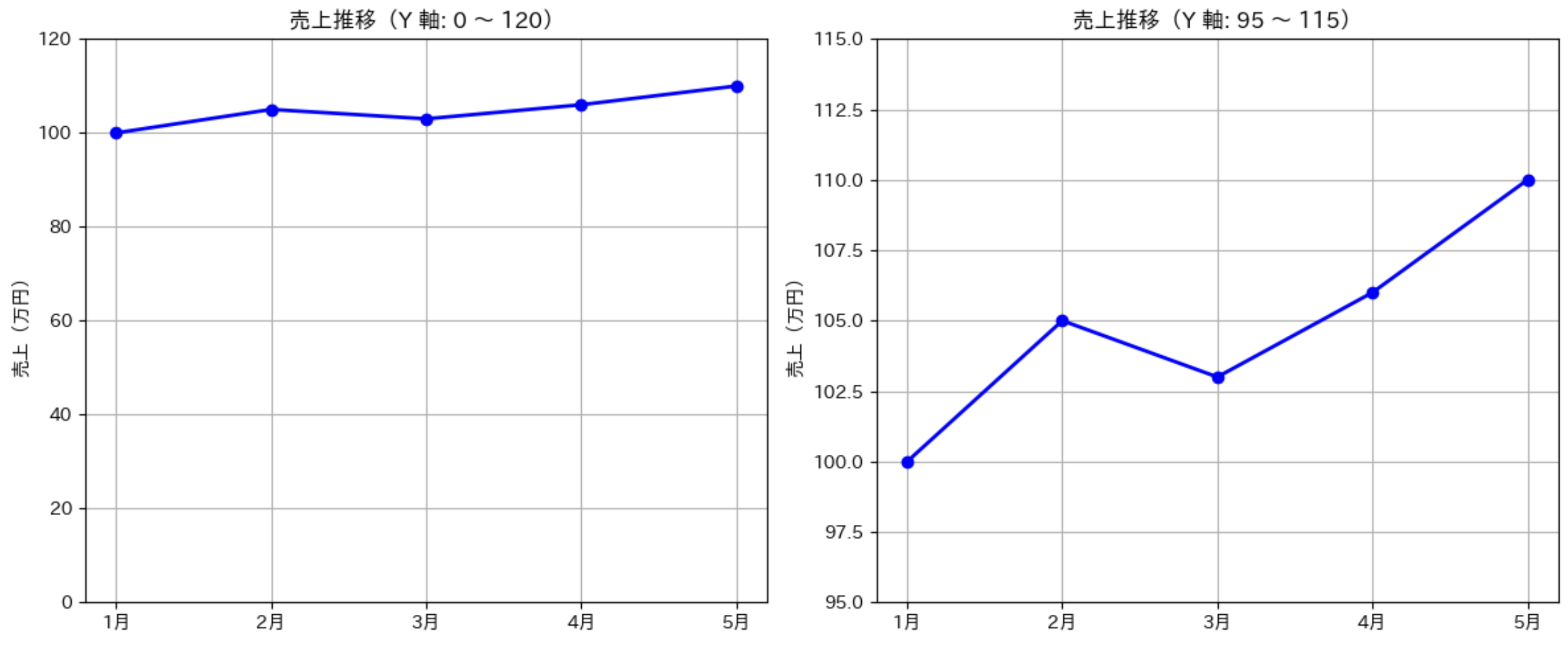
同じデータでも、Y 軸の範囲を変えるだけで印象が大きく変わります。左側のグラフでは、「変化が小さい」という印象になります。右側のグラフでは、「変化が大きい」という印象になります。
どちらが「正しい」というわけではありませんが、意図に応じて適切に選ぶことが重要です。
8.7 身近な情報をグラフ化してみよう
これまで様々なグラフの作成方法と可視化の重要性について学んできました。実践的な例として、身近な情報をグラフ化する方法を学びましょう。
身近なデータを収集する
まず、データ分析の第一歩は「データの収集」です。身の回りには様々なデータがあります:
- 部活動の練習時間や成績
- クラスの出席状況と成績分布
- 通学時間や交通手段の利用状況
日々の生活の中で自然と集まるものもあれば、意識的に記録する必要があるものもあります。今回は「部活動の練習時間データ」を例に考えてみましょう。
部活動の練習時間をグラフ化する
バスケットボール部の 1 週間の練習時間データを例に、グラフ化してみましょう。朝練と放課後の練習時間を記録しています。
部活動の練習時間データ
import matplotlib.pyplot as plt
import japanize_matplotlib
# 部活動の練習時間データ
days = ['月', '火', '水', '木', '金']
morning = [30, 45, 30, 45, 30] # 朝練時間 (分)
evening = [90, 60, 90, 60, 90] # 放課後練習時間 (分)
# 積み上げ棒グラフの作成
plt.figure(figsize=(10, 6))
plt.bar(days, morning, label='朝練', color='lightblue')
plt.bar(days, evening, bottom=morning, label='放課後', color='royalblue')
# グラフの装飾
plt.title('バスケ部の週間練習時間', fontsize=15)
plt.xlabel('曜日', fontsize=12)
plt.ylabel('練習時間(分)', fontsize=12)
plt.legend(loc='upper right')
plt.grid(True, axis='y', linestyle='--', alpha=0.7)
# 合計時間を表示
for i in range(len(days)):
total = morning[i] + evening[i]
plt.text(i, total + 5, f'計{total}分', ha='center')
plt.tight_layout()
plt.show()
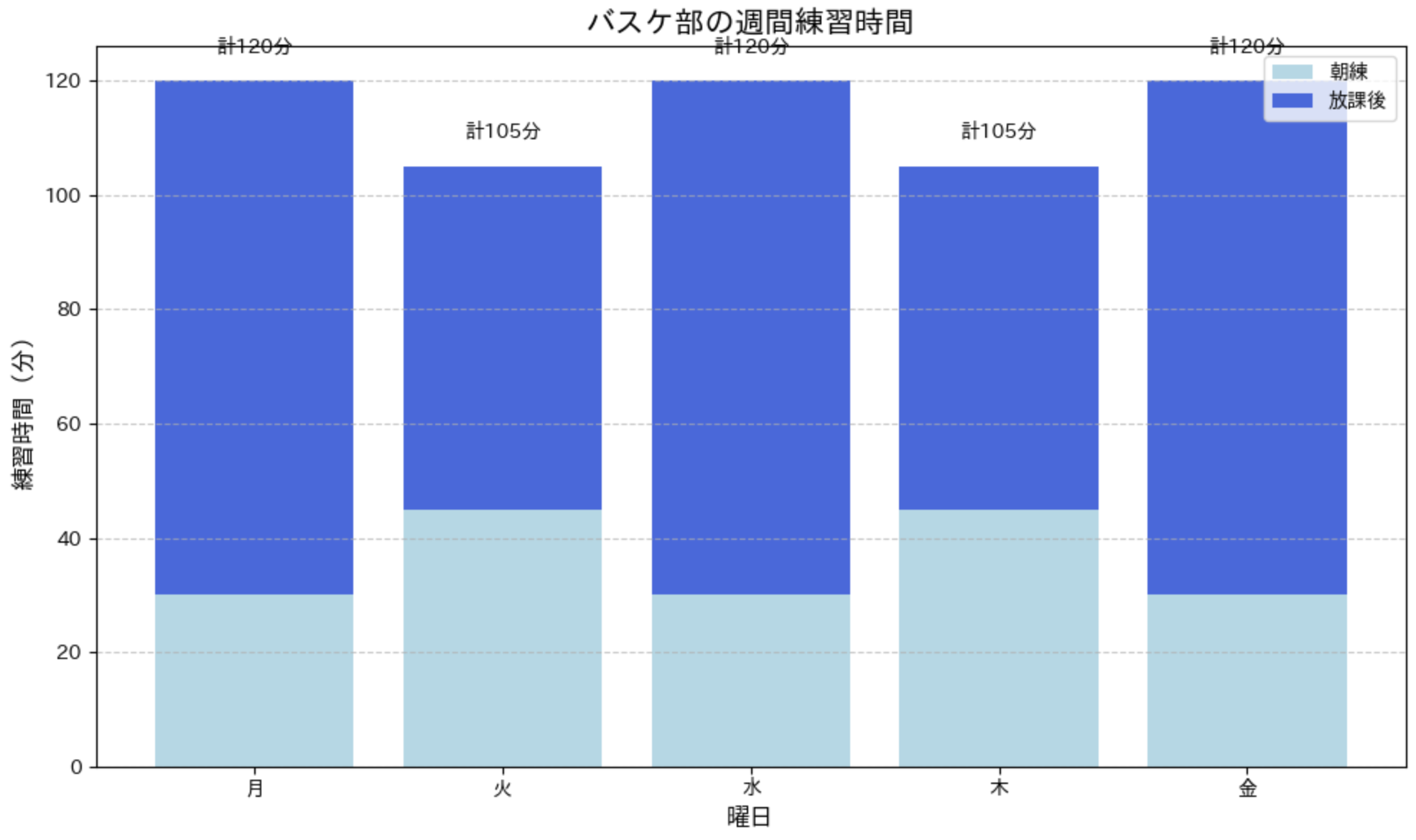
このグラフでは、積み上げ棒グラフを使って朝練と放課後の練習時間を視覚化しています。各棒の上に合計時間を表示することで、一目で総練習時間が分かるようにしています。
複数週間のデータを比較する
次に、複数週間のデータを比較してみましょう。例えば、通常週と大会前週の練習時間を比較します。
練習時間の週間比較
import matplotlib.pyplot as plt
import numpy as np
# 練習時間データ (2 週間分)
days = ['月', '火', '水', '木', '金']
# 通常週の練習時間 (分)
normal_week = [120, 105, 120, 105, 120]
# 大会前週の練習時間 (分)
tournament_week = [150, 135, 150, 140, 120]
# グラフの作成
plt.figure(figsize=(10, 6))
# X軸の位置を計算
x = np.arange(len(days))
width = 0.35 # 棒の幅
# 2 つの週のデータをプロット
plt.bar(x - width / 2, normal_week, width, label='通常週', color='lightblue')
plt.bar(x + width / 2, tournament_week, width, label='大会前週', color='salmon')
# グラフの装飾
plt.title('バスケ部の練習時間比較: 通常週 vs 大会前週', fontsize=15)
plt.xlabel('曜日', fontsize=12)
plt.ylabel('練習時間(分)', fontsize=12)
plt.xticks(x, days)
plt.legend()
plt.grid(True, axis='y', linestyle='--', alpha=0.7)
# 差分を表示
for i in range(len(days)):
diff = tournament_week[i] - normal_week[i]
if diff != 0:
plt.text(
i + width / 2,
tournament_week[i] + 5,
f'+{diff}' if diff > 0 else f'{diff}',
ha='center',
color='red' if diff > 0 else 'blue'
)
plt.tight_layout()
plt.show()
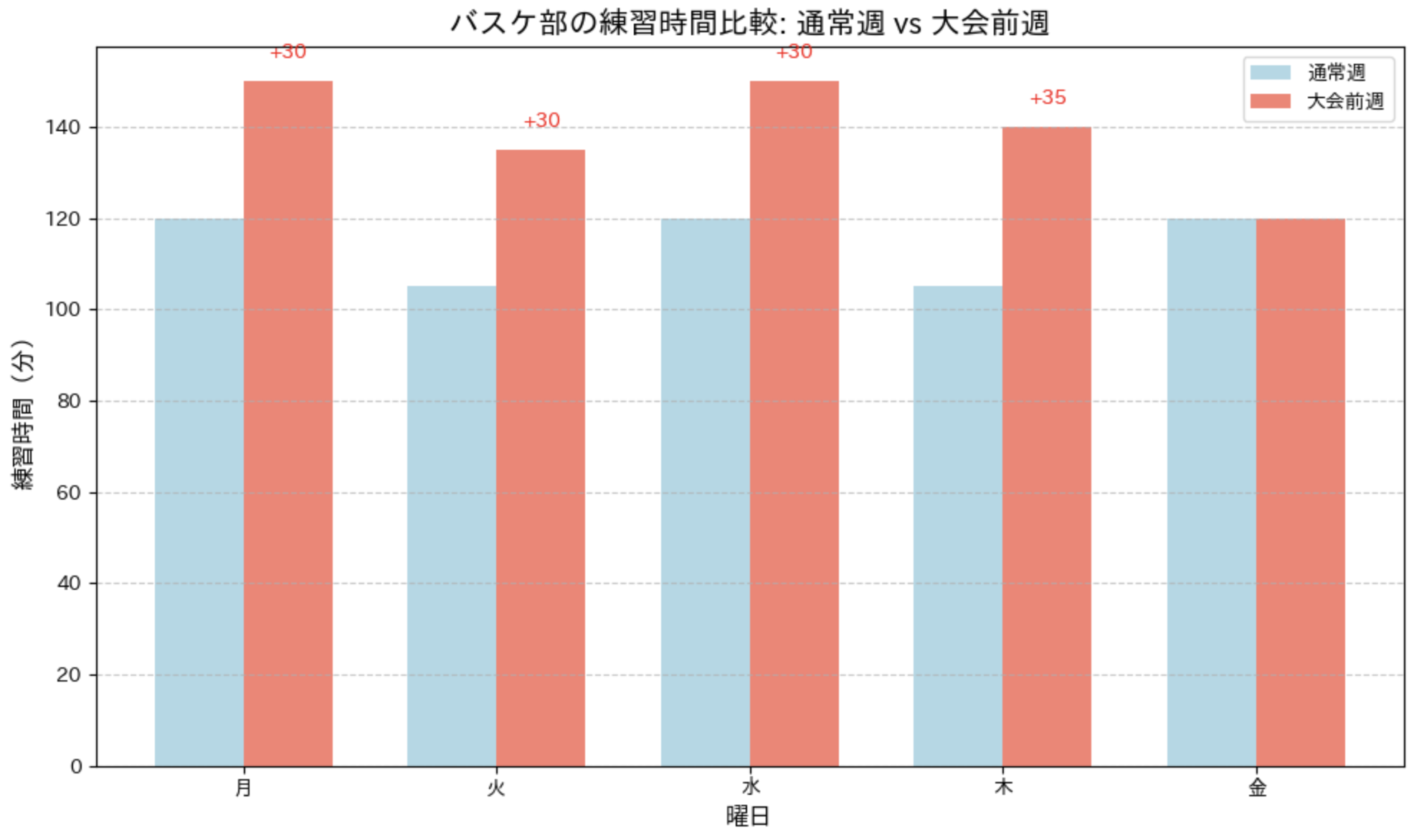
このグラフでは、通常週と大会前週の練習時間を横に並べた棒グラフで比較しています。さらに、大会前週で増減した時間も表示することで、違いが一目で分かるようにしています。
練習内容の内訳を円グラフで表現
練習時間だけでなく、練習内容の内訳も可視化してみましょう。
練習内容の内訳
import matplotlib.pyplot as plt
import japanize_matplotlib
# 練習内容の内訳データ (1 週間の合計時間)
practice_contents = {
'シュート練習': 120,
'パス練習': 90,
'ドリブル練習': 60,
'体力トレーニング': 75,
'ゲーム形式': 150,
'ミーティング': 45
}
# 色のリスト
colors = ['lightblue', 'lightgreen', 'lightsalmon', 'lightgray', 'gold', 'plum']
# 円グラフの作成
plt.figure(figsize=(10, 8))
plt.pie(practice_contents.values(),
labels=practice_contents.keys(),
autopct='%1.1f%%', # パーセント表示
startangle=90, # 開始角度
colors=colors)
plt.title('1週間の練習内容の内訳', fontsize=15)
plt.axis('equal') # 円を歪ませない
# 凡例を追加 (時間も表示)
legend_labels = [f"{k} ({v}分)" for k, v in practice_contents.items()]
plt.legend(legend_labels, loc='center left', bbox_to_anchor=(1, 0.4))
plt.tight_layout()
plt.show()
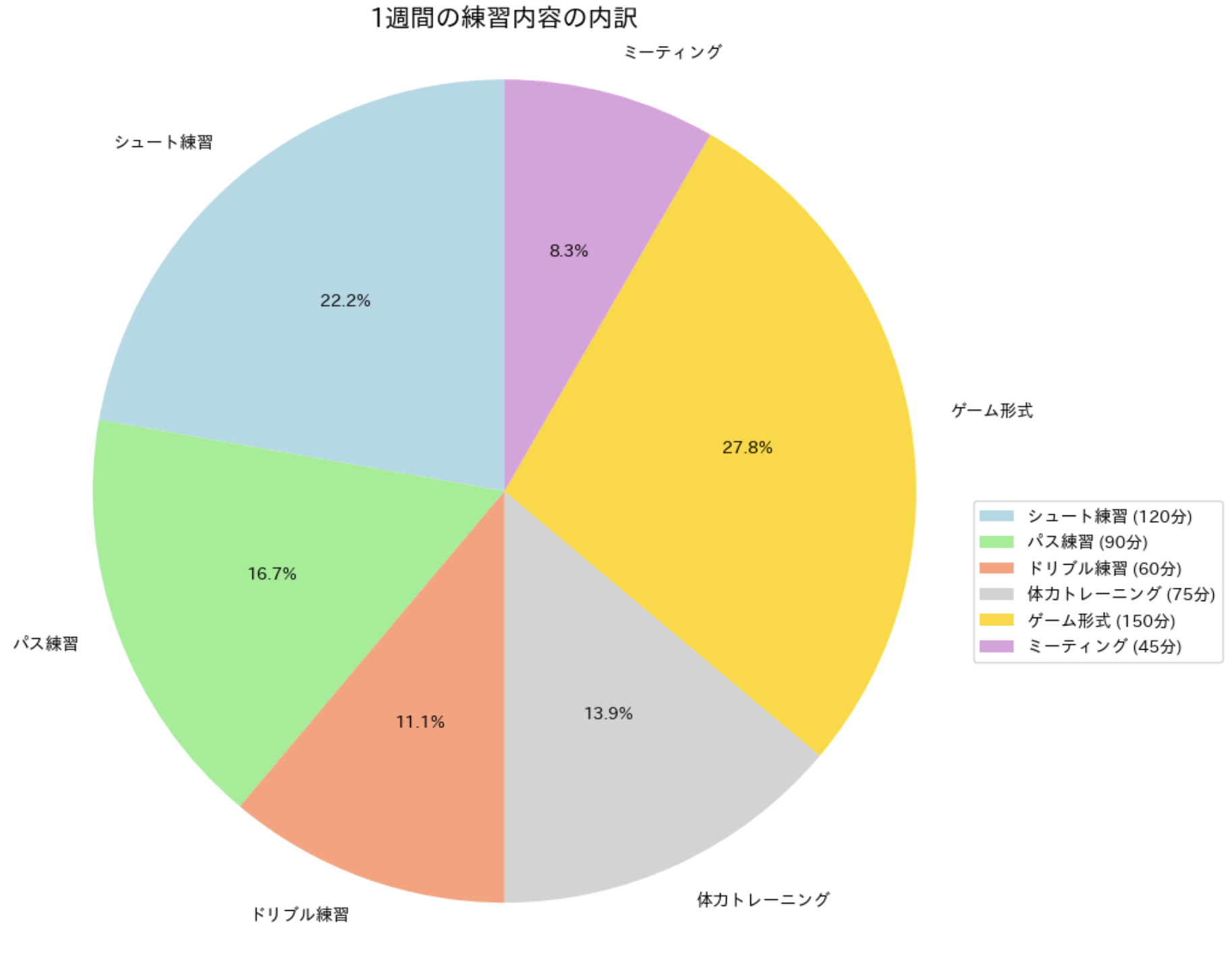
円グラフを使うことで、練習内容の割合が一目で分かります。凡例に実際の時間も表示することで、より詳細な情報も伝えています。
具体的なグラフをいくつか見てみると、データ分析の便利さが少し分かったと思います。どのようにデータを分析するかは工夫が必要ですが、生成 AI も頼りにしつつ、目的や必要なデータが何なのかなどを考えてみると理解が深まります!
Ex.1 クラス全員の点数をグラフ化し、平均点を表示するプログラム
クラス全員の点数をグラフ化し、平均点を表示するプログラム
import matplotlib.pyplot as plt
import numpy as np
import japanize_matplotlib
def visualize_class_scores():
students = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J']
scores = [85, 92, 78, 88, 95, 73, 89, 84, 91, 87]
# 平均点の計算
average = np.mean(scores)
# グラフの作成
plt.figure(figsize=(12, 6))
# 棒グラフの描画
bars = plt.bar(students, scores, color='skyblue')
# 平均点の線を追加
plt.axhline(y=average, color='red', linestyle='--', label=f'平均点: {average:.1f}')
# グラフの装飾
plt.title('クラスのテスト結果', fontsize=14, pad=15)
plt.xlabel('生徒', fontsize=12)
plt.ylabel('点数', fontsize=12)
plt.grid(True, linestyle='--', alpha=0.3)
plt.legend()
# 各棒グラフの上に点数を表示
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2., height, f'{int(height)}', ha='center', va='bottom')
plt.show()
visualize_class_scores()
チャレンジ:
- 点数が平均点を下回っている生徒を異なる色で表示してみよう
- 各生徒の点数を前回のテストと比較する折れ線グラフを追加してみよう
- 成績評価(A, B, C, D, F)を基準に応じて各棒グラフに表示してみよう
Ex.2 部活動の練習日数を棒グラフで表示し、タイトルやラベルを付けるプログラム
部活動の練習日数を棒グラフで表示し、タイトルやラベルを付けるプログラム
import matplotlib.pyplot as plt
import japanize_matplotlib
def visualize_club_activities():
# 月ごとの練習日数データ
months = ['4月', '5月', '6月', '7月', '8月', '9月']
regular_days = [15, 18, 20, 16, 22, 19] # 通常練習
special_days = [2, 3, 5, 8, 10, 4] # 特別練習
# グラフのサイズ設定
plt.figure(figsize=(12, 7))
# バーの位置を計算
x = np.arange(len(months))
width = 0.35
# 棒グラフの作成
plt.bar(x - width/2, regular_days, width, label='通常練習',
color='lightblue')
plt.bar(x + width/2, special_days, width, label='特別練習',
color='lightgreen')
# グラフの装飾
plt.title('部活動月間練習日数', fontsize=14, pad=15)
plt.xlabel('月', fontsize=12)
plt.ylabel('練習日数', fontsize=12)
plt.xticks(x, months)
plt.legend()
plt.grid(True, linestyle='--', alpha=0.3)
# 各棒グラフの上に日数を表示
for i, v in enumerate(regular_days):
plt.text(i - width/2, v + 0.5, str(v), ha='center')
for i, v in enumerate(special_days):
plt.text(i + width/2, v + 0.5, str(v), ha='center')
# 合計日数を表示
total_days = [r + s for r, s in zip(regular_days, special_days)]
for i, total in enumerate(total_days):
plt.text(i, max(regular_days[i], special_days[i]) + 2, f'計{total}日', ha='center')
plt.show()
visualize_club_activities()
チャレンジ:
- 複数の部活動のデータを比較してみよう
- 練習時間も含めたグラフを作成してみよう
- 3 ヶ月ごとの推移を折れ線グラフで表示してみよう
まとめ
この章で学んだこと:
- 基本的な統計量の計算方法
- matplotlibによるグラフ作成の基本
- 様々なグラフの種類と使い分け
- グラフの見やすさを高める工夫
- 実践的なデータ可視化の方法